!pip install yfinanceInformer
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
import tensorflow as tf
import yfinance as yf# Download historical data as dataframe
data = yf.download("AAPL", start="2018-01-01", end="2025-02-01")The Informer model variant is designed for multivariate prediction. Let’s consider ‘Open’, ‘High’, ‘Low’, and ‘Close’ prices for simplicity. The provided code is designed to fetch and preprocess historical stock prices for Apple Inc. for the purpose of multivariate time series forecasting using an LSTM model. Initially, the code downloads Apple’s stock data, specifically capturing four significant features: Open, High, Low, and Close prices. To make the data suitable for deep learning models, it is normalized to fit within a range of 0 to 1. The sequential data is then transformed into a format suitable for supervised learning, where the data from the past look_back days is used to predict the next day’s features. Finally, the data is partitioned into training (67%) and test sets, ensuring separate datasets for model training and evaluation.
# Using multiple columns for multivariate prediction
df = data[["Open", "High", "Low", "Close"]]
# Normalize the data
scaler = MinMaxScaler(feature_range=(0, 1))
df_scaled = scaler.fit_transform(df)
# Prepare data for LSTM
look_back = 10 # Number of previous time steps to use as input variables
n_features = df.shape[1] # number of features
# Convert to supervised learning problem
X, y = [], []
for i in range(len(df_scaled) - look_back):
X.append(df_scaled[i:i+look_back, :])
y.append(df_scaled[i + look_back, :])
X, y = np.array(X), np.array(y)
# Reshape input to be [samples, time steps, features]
X = np.reshape(X, (X.shape[0], X.shape[1], n_features))
# Train-test split
train_size = int(len(X) * 0.67)
test_size = len(X) - train_size
X_train, X_test = X[0:train_size], X[train_size:]
y_train, y_test = y[0:train_size], y[train_size:]
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)(1186, 10, 4) (1186, 4) (585, 10, 4) (585, 4)ProbSparse Self-Attention:
Self-attention involves computing a weighted sum of all values in the sequence, based on the dot product between the query and key. In ProbSparse, we don’t compute this for all query-key pairs, but rather select dominant ones, thus making the computation more efficient. The given code defines a custom Keras layer, ProbSparseSelfAttention, which implements the multi-head self-attention mechanism, a critical component of Transformer models. This layer initializes three dense networks for the Query, Key, and Value matrices, and splits the input data into multiple heads to enable parallel processing. During the forward pass (call method), the Query, Key, and Value matrices are calculated, scaled, and then used to compute attention scores. These scores indicate the importance of each element in the sequence when predicting another element. The output is a weighted sum of the input values, which is then passed through another dense layer to produce the final result.
class ProbSparseSelfAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, **kwargs):
super(ProbSparseSelfAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.d_model = d_model
# Assert that d_model is divisible by num_heads
assert self.d_model % self.num_heads == 0, f"d_model ({d_model}) must be divisible by num_heads ({num_heads})"
self.depth = d_model // self.num_heads
# Defining the dense layers for Query, Key and Value
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q):
batch_size = tf.shape(q)[0]
q = self.wq(q)
k = self.wk(k)
v = self.wv(v)
q = self.split_heads(q, batch_size)
k = self.split_heads(k, batch_size)
v = self.split_heads(v, batch_size)
# Fixing matrix multiplication
matmul_qk = tf.matmul(q, k, transpose_b=True)
d_k = tf.cast(self.depth, tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(d_k)
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1)
output = tf.matmul(attention_weights, v)
output = tf.transpose(output, perm=[0, 2, 1, 3])
concat_attention = tf.reshape(output, (batch_size, -1, self.d_model))
return self.dense(concat_attention)Informer Encoder:
The InformerEncoder is a custom Keras layer designed to process sequential data using a combination of attention and convolutional mechanisms. Within the encoder, the input data undergoes multi-head self-attention, utilizing the ProbSparseSelfAttention mechanism, to capture relationships in the data regardless of their distance. Post attention, the data is transformed and normalized, then further processed using two 1D convolutional layers, emphasizing local features in the data. After another normalization step, the processed data is pooled to a lower dimensionality, ensuring the model captures global context, and then passed through a dense layer to produce the final output.
class InformerEncoder(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, conv_filters, **kwargs):
super(InformerEncoder, self).__init__(**kwargs)
self.d_model = d_model
self.num_heads = num_heads
# Assert that d_model is divisible by num_heads
assert self.d_model % self.num_heads == 0, f"d_model ({d_model}) must be divisible by num_heads ({num_heads})"
self.self_attention = ProbSparseSelfAttention(d_model=d_model, num_heads=num_heads)
self.norm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
# This dense layer will transform the input 'x' to have the dimensionality 'd_model'
self.dense_transform = tf.keras.layers.Dense(d_model)
self.conv1 = tf.keras.layers.Conv1D(conv_filters, 3, padding='same')
self.conv2 = tf.keras.layers.Conv1D(d_model, 3, padding='same')
self.norm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.global_avg_pooling = tf.keras.layers.GlobalAveragePooling1D()
self.dense = tf.keras.layers.Dense(d_model)
def call(self, x):
attn_output = self.self_attention(x, x, x)
# Transform 'x' to have the desired dimensionality
x_transformed = self.dense_transform(x)
attn_output = self.norm1(attn_output + x_transformed)
conv_output = self.conv1(attn_output)
conv_output = tf.nn.relu(conv_output)
conv_output = self.conv2(conv_output)
encoded_output = self.norm2(conv_output + attn_output)
pooled_output = self.global_avg_pooling(encoded_output)
return self.dense(pooled_output)[:, -4:]
input_layer = tf.keras.layers.Input(shape=(look_back, n_features))
# Encoder
encoder_output = InformerEncoder(d_model=360, num_heads=8, conv_filters=64)(input_layer)
# Decoder (with attention)
decoder_lstm = tf.keras.layersThe InformerModel function is designed to create a deep learning architecture tailored for sequential data prediction. It takes an input sequence and processes it using the InformerEncoder, a custom encoder layer, which captures both local and global patterns in the data. Following the encoding step, a decoder structure unravels the encoded data by first repeating the encoder’s output, then passing it through an LSTM layer to retain sequential dependencies, and finally making predictions using a dense layer. The resulting architecture is then compiled with the Adam optimizer and Mean Squared Error loss, ready for training on time series data.
from tensorflow.keras.layers import RepeatVector
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import LSTM
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
def InformerModel(input_shape, d_model=64, num_heads=2, conv_filters=256, learning_rate= 1e-3):
# Input
input_layer = Input(shape=input_shape)
# Encoder
encoder_output = InformerEncoder(d_model=d_model, num_heads=num_heads, conv_filters=conv_filters)(input_layer)
# Decoder
repeated_output = RepeatVector(4)(encoder_output) # Repeating encoder's output
decoder_lstm = LSTM(312, return_sequences=True)(repeated_output)
decoder_output = Dense(4)(decoder_lstm[:, -1, :]) # Use the last sequence output to predict the next value
# Model
model = Model(inputs=input_layer, outputs=decoder_output)
# Compile the model with the specified learning rate
optimizer = Adam(learning_rate=learning_rate)
model.compile(optimizer=optimizer, loss='mean_squared_error')
return model
model = InformerModel(input_shape=(look_back, n_features))
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
Model: "functional_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩ │ input_layer_3 (InputLayer) │ (None, 10, 4) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ informer_encoder_3 (InformerEncoder) │ (None, 4) │ 108,480 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ repeat_vector_1 (RepeatVector) │ (None, 4, 4) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ lstm_1 (LSTM) │ (None, 4, 312) │ 395,616 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ get_item_1 (GetItem) │ (None, 312) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dense_25 (Dense) │ (None, 4) │ 1,252 │ └──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 505,348 (1.93 MB)
Trainable params: 505,348 (1.93 MB)
Non-trainable params: 0 (0.00 B)
The model.fit method trains the neural network using the provided training data (X_train and y_train) for a total of 50 epochs with mini-batches of 32 samples. During training, 20% of the training data is set aside for validation to monitor and prevent overfitting.
history = model.fit(
X_train, y_train,
epochs=50,
batch_size=32,
validation_split=0.2,
shuffle=True
)Epoch 1/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 5s 31ms/step - loss: 0.0154 - val_loss: 0.0018 Epoch 2/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 0.0010 - val_loss: 0.0043 Epoch 3/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 5.1550e-04 - val_loss: 0.0028 Epoch 4/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 2.7563e-04 - val_loss: 0.0030 Epoch 5/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.9865e-04 - val_loss: 0.0020 Epoch 6/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 5.2677e-04 - val_loss: 0.0047 Epoch 7/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 2.6547e-04 - val_loss: 0.0028 Epoch 8/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 4.0132e-04 - val_loss: 0.0041 Epoch 9/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 4.1915e-04 - val_loss: 0.0020 Epoch 10/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 2.0107e-04 - val_loss: 0.0021 Epoch 11/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 2.0719e-04 - val_loss: 0.0016 Epoch 12/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.9808e-04 - val_loss: 0.0026 Epoch 13/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 2.8400e-04 - val_loss: 0.0034 Epoch 14/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 2.3300e-04 - val_loss: 0.0012 Epoch 15/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 2.1247e-04 - val_loss: 0.0027 Epoch 16/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 13ms/step - loss: 3.0323e-04 - val_loss: 0.0041 Epoch 17/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 2.7985e-04 - val_loss: 0.0015 Epoch 18/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.5797e-04 - val_loss: 6.6577e-04 Epoch 19/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 5.4085e-04 - val_loss: 0.0030 Epoch 20/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.9506e-04 - val_loss: 8.3417e-04 Epoch 21/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.3297e-04 - val_loss: 6.5254e-04 Epoch 22/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.3551e-04 - val_loss: 4.5622e-04 Epoch 23/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.0705e-04 - val_loss: 0.0013 Epoch 24/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.1402e-04 - val_loss: 8.5076e-04 Epoch 25/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 9.5359e-05 - val_loss: 0.0012 Epoch 26/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.3278e-04 - val_loss: 6.5595e-04 Epoch 27/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 6.7347e-05 - val_loss: 3.6600e-04 Epoch 28/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 9.0798e-05 - val_loss: 0.0012 Epoch 29/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 8.6695e-05 - val_loss: 0.0031 Epoch 30/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 4.9864e-04 - val_loss: 0.0014 Epoch 31/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.3068e-04 - val_loss: 7.0472e-04 Epoch 32/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.1008e-04 - val_loss: 3.9942e-04 Epoch 33/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.0097e-04 - val_loss: 7.5198e-04 Epoch 34/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 6.4572e-05 - val_loss: 7.3072e-04 Epoch 35/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 7.1244e-05 - val_loss: 4.2629e-04 Epoch 36/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.2428e-04 - val_loss: 5.8915e-04 Epoch 37/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.0478e-04 - val_loss: 3.9770e-04 Epoch 38/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 8.0380e-05 - val_loss: 5.6696e-04 Epoch 39/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 7.2923e-05 - val_loss: 3.0246e-04 Epoch 40/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.0972e-04 - val_loss: 0.0017 Epoch 41/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 8.6855e-05 - val_loss: 3.1164e-04 Epoch 42/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.4452e-04 - val_loss: 0.0048 Epoch 43/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 3.2589e-04 - val_loss: 5.1901e-04 Epoch 44/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 13ms/step - loss: 1.5365e-04 - val_loss: 0.0029 Epoch 45/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.4573e-04 - val_loss: 7.3239e-04 Epoch 46/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 7.9229e-05 - val_loss: 4.8256e-04 Epoch 47/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 5.8039e-05 - val_loss: 6.5187e-04 Epoch 48/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 9.0029e-05 - val_loss: 3.8118e-04 Epoch 49/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 8.2436e-05 - val_loss: 4.7878e-04 Epoch 50/50 30/30 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step - loss: 1.0576e-04 - val_loss: 9.0716e-04
The code displays a visual representation of the model’s training and validation loss over the epochs using a line chart. The x-axis represents the number of epochs, while the y-axis indicates the mean squared error, allowing users to observe how the model’s performance evolves over time.
plt.figure(figsize=(12, 6))
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Mean Squared Error')
plt.legend()
plt.show()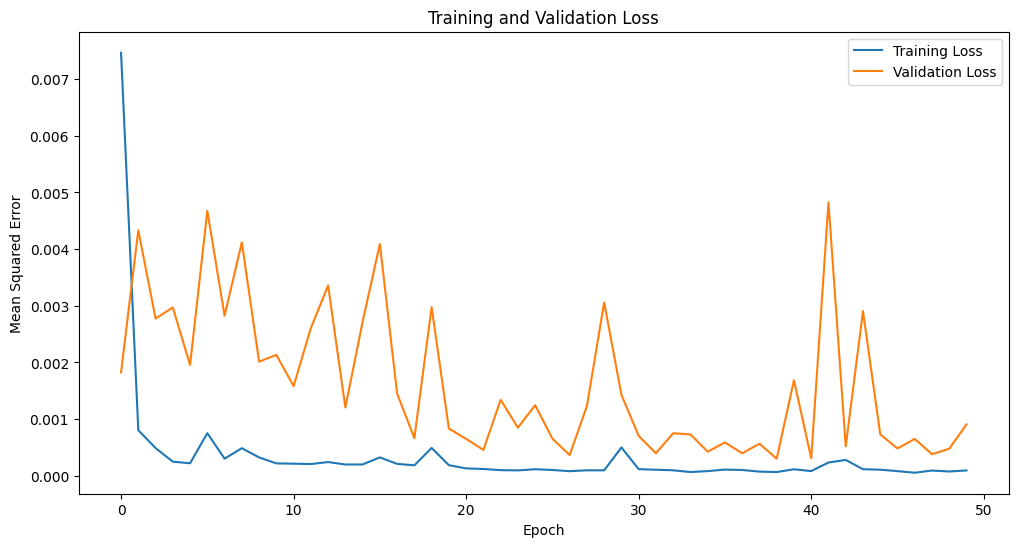
test_predictions = model.predict(X_test)
test_predictions = scaler.inverse_transform(test_predictions)
true_values = scaler.inverse_transform(y_test)
mse = mean_squared_error(true_values, test_predictions)
print(f"Test MSE: {mse}")19/19 ━━━━━━━━━━━━━━━━━━━━ 1s 20ms/step Test MSE: 417.9734010119239
plt.figure(figsize=(12, 6))
plt.plot(true_values, label='True Values')
plt.plot(test_predictions, label='Predictions', alpha=0.6)
plt.title('Test Set Predictions vs. True Values')
plt.legend()
plt.show()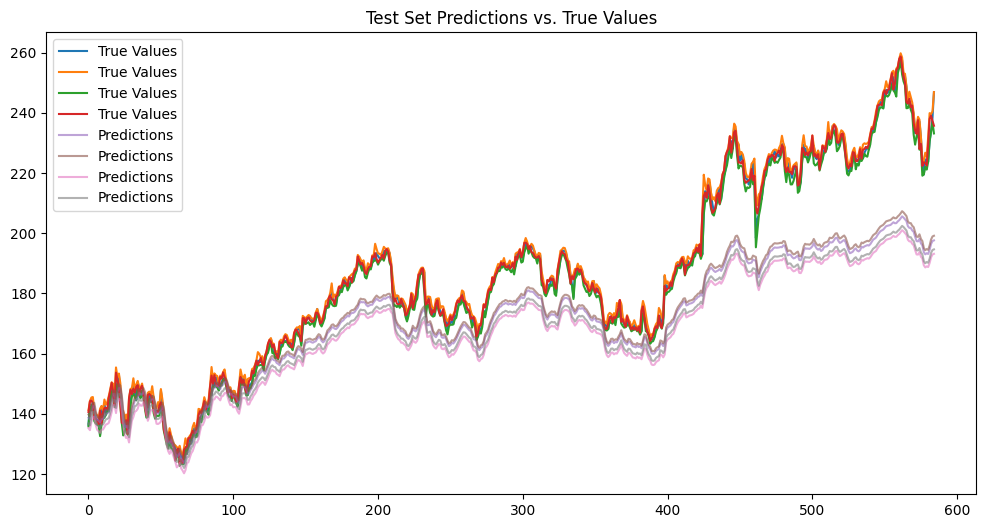
!pip install keras-tunerThe code defines a function to construct a neural network model using varying hyperparameters, aiming to optimize its architecture. Subsequently, the RandomSearch method from Keras Tuner is employed to explore 200 different model configurations, assessing their performance to determine the best hyperparameters that minimize the validation loss.
from tensorflow.keras.layers import Input, RepeatVector, LSTM, Dense
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
import tensorflow as tf
import kerastuner as kt
def build_model(hp):
# Input
input_layer = Input(shape=(look_back, n_features))
# Encoder
encoder_output = InformerEncoder(d_model=hp.Int('d_model', min_value=32, max_value=512, step=16),
num_heads=hp.Int('num_heads', 2, 8, step=2),
conv_filters=hp.Int('conv_filters', min_value=16, max_value=256, step=16))(input_layer)
# Decoder
repeated_output = RepeatVector(4)(encoder_output) # Repeating encoder's output
decoder_lstm = LSTM(312, return_sequences=True)(repeated_output)
decoder_output = Dense(4)(decoder_lstm[:, -1, :]) # Use the last sequence output to predict the next value
# Model
model = Model(inputs=input_layer, outputs=decoder_output)
# Compile the model with the specified learning rate
optimizer = Adam(learning_rate=hp.Choice('learning_rate', [1e-3, 1e-2, 1e-1]))
model.compile(optimizer=optimizer, loss='mean_squared_error')
return model
# Define the tuner
tuner = kt.RandomSearch(
build_model,
objective='val_loss',
max_trials=2,
executions_per_trial=5,
directory='hyperparam_search',
project_name='informer_model'
)The code sets up two training callbacks: one for early stopping if validation loss doesn’t improve after 10 epochs, and another to save the model weights at their best performance. With these callbacks, the tuner conducts a search over the hyperparameter space using the training data, and evaluates model configurations over 100 epochs, saving the most optimal weights and potentially halting early if improvements stagnate.
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
early_stopping = EarlyStopping(monitor='val_loss', patience=10, verbose=1, restore_best_weights=True)
model_checkpoint = ModelCheckpoint(filepath='trial_best.h5', monitor='val_loss', verbose=1, save_best_only=True)
tuner.search(X_train, y_train,
epochs=100,
validation_split=0.2,
callbacks=[early_stopping, model_checkpoint])Trial 2 Complete [00h 01m 16s]
val_loss: 0.03971799267455935
Best val_loss So Far: 0.03836521059274674
Total elapsed time: 00h 02m 32s# Get the best hyperparameters
best_hp = tuner.get_best_hyperparameters()[0]
# Retrieve the best model
best_model = tuner.get_best_models()[0]
best_model.summary()Model: "functional"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩ │ input_layer (InputLayer) │ (None, 10, 4) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ informer_encoder (InformerEncoder) │ (None, 4) │ 397,440 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ repeat_vector (RepeatVector) │ (None, 4, 4) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ lstm (LSTM) │ (None, 4, 312) │ 395,616 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ get_item (GetItem) │ (None, 312) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dense_6 (Dense) │ (None, 4) │ 1,252 │ └──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 794,308 (3.03 MB)
Trainable params: 794,308 (3.03 MB)
Non-trainable params: 0 (0.00 B)
test_loss = best_model.evaluate(X_test, y_test)
print(f"Test MSE: {test_loss}")19/19 ━━━━━━━━━━━━━━━━━━━━ 1s 6ms/step - loss: 0.0468 Test MSE: 0.09702601283788681
plt.figure(figsize=(20, 12))
for i in range(true_values.shape[1]):
plt.subplot(2, 2, i+1)
plt.plot(true_values[:, i], label='True Values', color='blue')
plt.plot(test_predictions[:, i], label='Predictions', color='red', linestyle='--')
plt.title(f"Feature {i+1}")
plt.legend()
plt.tight_layout()
plt.show()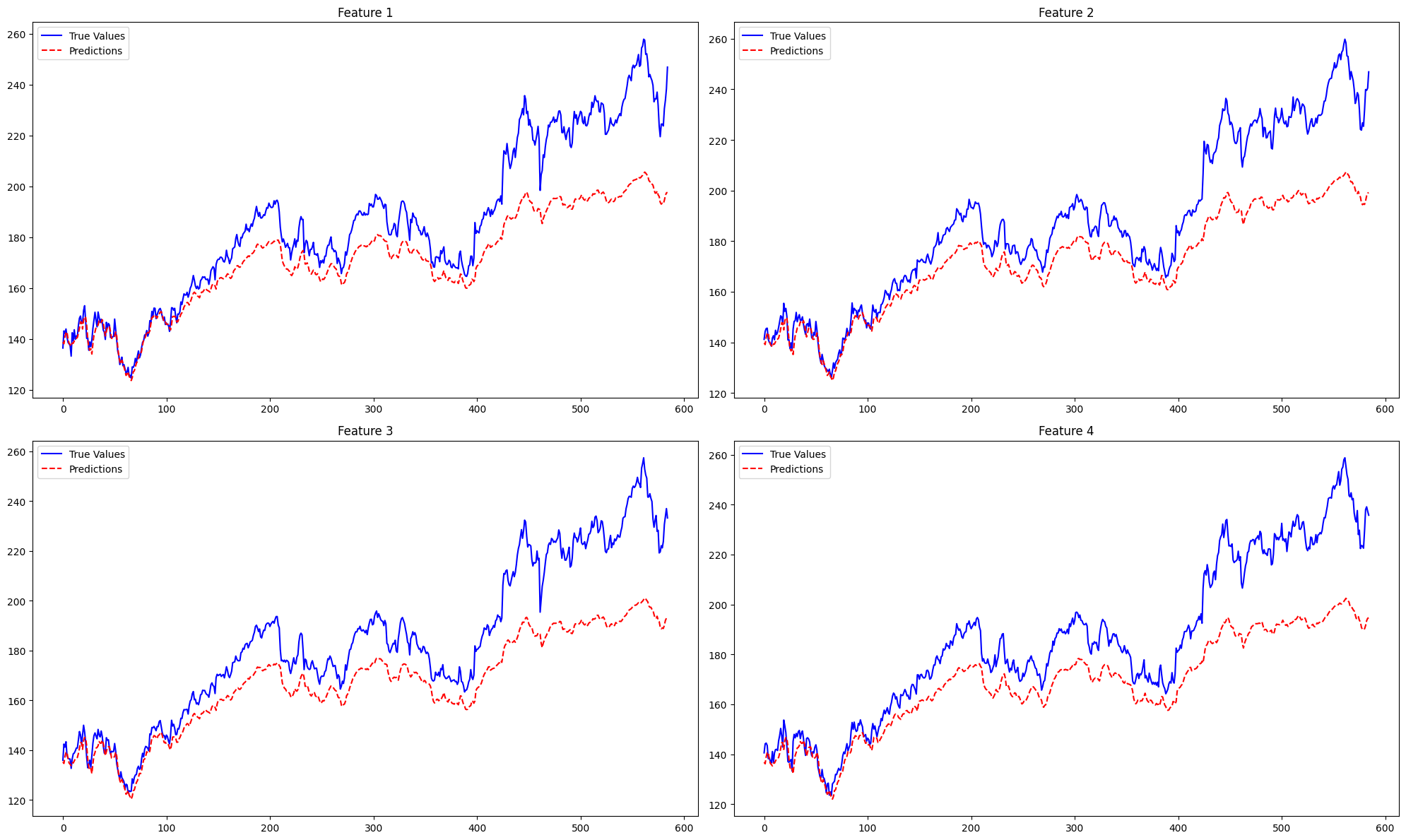
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(true_values, test_predictions)
rmse = np.sqrt(test_loss) # since loss is MSE
print(f"MAE: {mae}, RMSE: {rmse}")MAE: 15.963517723233736, RMSE: 0.31148998834294306print(f"Best d_model: {best_hp.get('d_model')}")
print(f"Best num_heads: {best_hp.get('num_heads')}")
print(f"Best conv_filters: {best_hp.get('conv_filters')}")
print(f"Best learning_rate: {best_hp.get('learning_rate')}")Best d_model: 304
Best num_heads: 4
Best conv_filters: 112
Best learning_rate: 0.1